Harness 就是产品:一个工程师,两周,600+ 任务
Claude Code 是一个 harness,但那是别人的 harness。 从 GovTech 工程师 Ng Shangru 的 Terra 系统拆解多 Agent 编排的方法论: harness 才是真正的 moat、组件是被痛点逼出来的、 Planner-Debater-Coder 流水线优于单个 Opus、 state.json 让会话只是看向 ground truth 的窗口。

一个工程师,两周,600+ 任务:当你开始为 Claude Code 写”调度系统”
TL;DR:Claude Code 是一个 harness,但那是别人的 harness,不是你的。GovTech 工程师 Ng Shangru 在两周内搭出了 Terra —— 一个一个人调度 600+ 任务的多 Agent 编排系统。核心方法论:harness 才是真正的 moat(不在模型层)、每个组件都是被痛点逼出来的而不是设计出来的、Planner-Debater-Coder 流水线 + Sonnet 优于单个 Opus、
state.json让会话只是看向 ground truth 的窗口。
一、从一个钢铁侠的画面说起
《钢铁侠 3》最后有个名场面:Tony Stark 启动 “House Party Protocol”,35 套战甲从地下基地全部起飞。Stark 没有挨个指挥,他只给 JARVIS 下高层指令——派哪些过去、哪些撤回、哪些去支援谁——剩下的执行交给战甲自己。
如果这不是多 Agent 编排,那什么才是?
最近读到 GovTech 工程师 Ng Shangru 写的一篇长文《Harnessing the Harness》,讲他怎么从一个 shell 脚本起步,两周内搭出了一个叫 Terra 的多 Agent 编排系统,让一个人完成了 600+ 个任务。这篇文章给我最深的触动不是”他做了什么”,而是他点出了一个所有用 Claude Code 的人迟早会撞上的墙——以及为什么这堵墙没法靠”等更好的模型”翻过去。
我把他的方法论拆解了一遍,结合自己的理解,写成这篇可以直接动手照做的指南。
二、先建一个领域模型:什么是 “harness”?
在写代码之前,我习惯先把概念厘清。原文用了一个核心词 harness——直译”挽具”,就是套在马身上、让你能驾驭它的那套绳索皮带。
放到 AI 工程里,harness 指的是包在模型外面的所有东西:上下文怎么注入、工具怎么调用、状态怎么持久化、多个会话怎么协同。Claude Code 本身就是一个非常优秀的 harness——CLAUDE.md 文件、hooks、memory、skills,这些都是它的”挽具组件”。
但作者的观点很尖锐:
Claude Code 是一个 harness,但那是别人的 harness,不是你的。
这就引出了一个关键的领域区分:
| 层级 | 你能控制的 | 你不能控制的 |
|---|---|---|
| 模型层(Sonnet/Opus) | 选哪个模型 | 模型本身的能力 |
| Claude Code harness | 你的 CLAUDE.md、skills、hooks | 它的 compaction 逻辑、会话生命周期、跨端同步 |
| 你自己的 harness | 全部 | —— |
moat(护城河)不在模型层,也不完全在 Claude Code 这一层,而在最外面那一层——只有你自己写的那部分。
这是整个领域模型的根。后面所有的方法论都从这里推导出来。
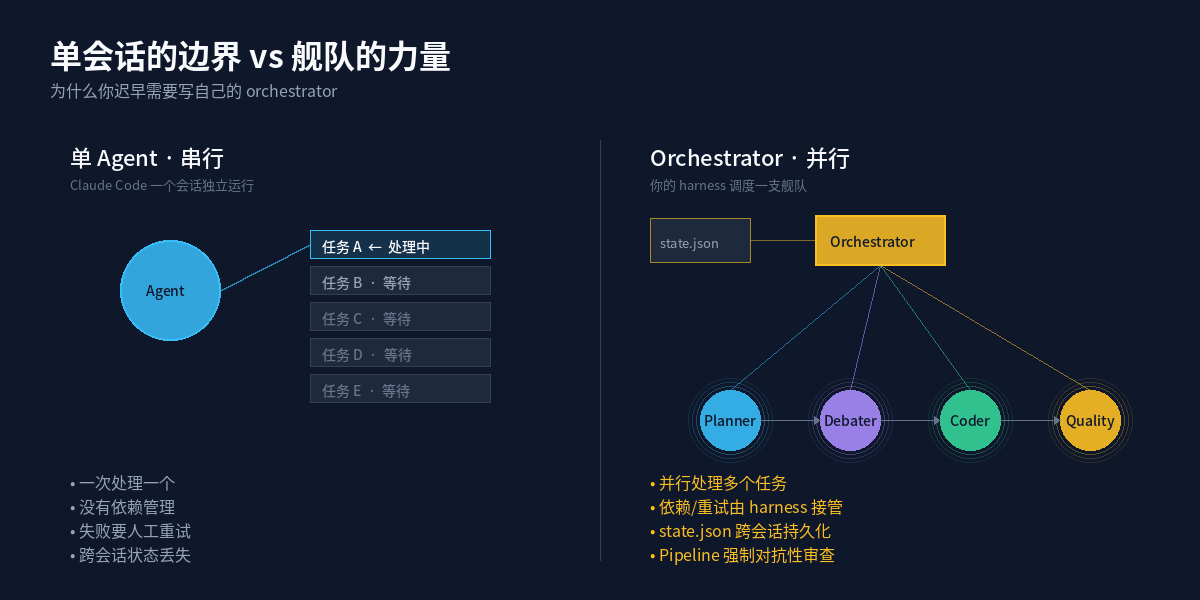
三、单会话的天花板:你迟早会撞上的三堵墙
为什么需要自己写 harness?因为 Claude Code 作为单会话工具非常出色,但一旦你的工作不是”一件事”而是”一摊事”,三个问题会同时浮现。
墙 1:Compaction 失忆
Claude Code 会话跑久了,上下文窗口会满。系统会自动压缩——总结对话历史腾出空间。
听起来很合理,但作者用了一个特别准的类比:压缩不是按”最近发生的事”加权的。Agent 知道整个故事的大意,但不记得它刚刚读到的那一章发生了什么。
Orchestrator 从 compaction 里醒过来,就像卡通片里被砸晕的角色:它知道自己是谁、在哪工作,但完全不记得五分钟前在干嘛。
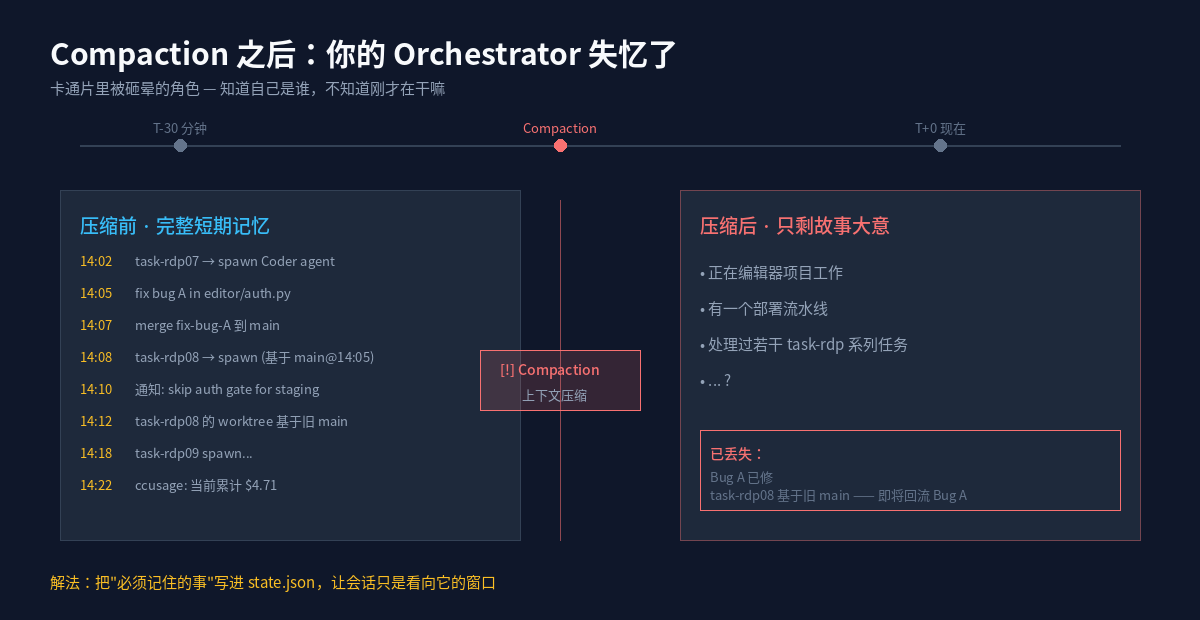
单任务里这无所谓,但当你的 orchestrator 同时管着 20 个 Agent、横跨 5 个项目、上百个任务时——这是灾难。
更糟的是回流问题:你修了 Bug A 并 merge 了,但 Agent B 在 merge 之前就 fork 出去工作了。等 B 干完,orchestrator 已经因为 compaction 忘了 Bug A 存在,开开心心把 B 的分支 merge 回来——Bug A 又回来了。
墙 2:状态没有持久化
会话崩了、watchdog 重启、第二天换个终端——所有上下文清零。Claude Code 不会替你记住”我正要 merge task-rdp07,而 task-rdp08 和 editor 分支有依赖冲突”。每次都得从头重建。
墙 3:跨端断裂
你在终端干活,出门要从手机查进度。终端的会话和 Telegram 的 bot 是两个孤岛——除非你自己搭桥。Claude Code 现在有了跨端续聊,但“继续一段对话”和”操作一支舰队”是两件事。从手机问”editor 项目现在什么状态”,你要的不是聊天续接,而是查询整个系统的实时状态。
这三堵墙的本质是同一件事:单会话工具的边界,就是你 harness 的起点。
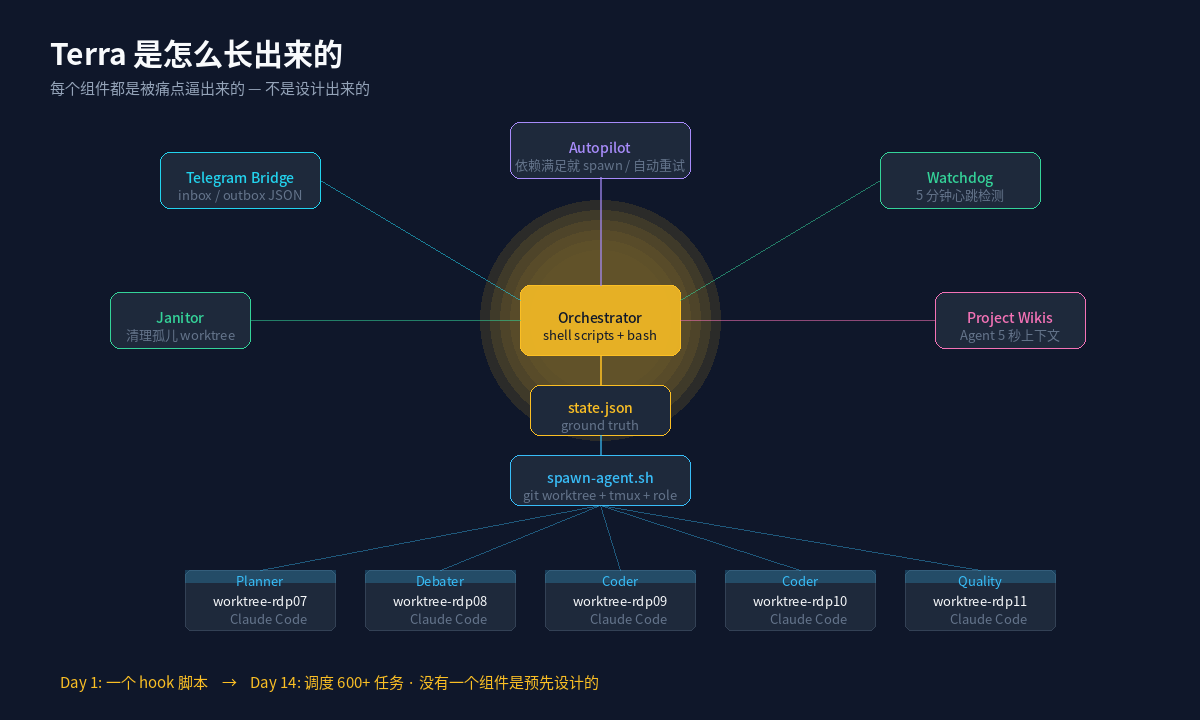
四、Terra 的演化轨迹:每个功能都是被打疼了才加的
作者一个反复强调的洞察是:你不知道自己需要什么,直到你感受到什么是缺的。
Terra 的演化路径特别能说明这点,我按时间轴还原一下:
Day 1:一个 PostToolUse hook,检查 JSON 文件里有没有 Telegram 来的未处理消息。就这么一行 shell 脚本。
Day 2:加了 check-agents.sh 和 spawn-agent.sh。后者干这些事:
- 创建一个 git worktree(隔离工作目录)
- 把对应角色的 CLAUDE.md 拷进去
- 把任务 JSON 放进去
- 在 tmux 里启动一个 Claude Code 会话
- 让 Agent 自己干活、提交、改状态、退出
一行命令搞定:
1
spawn-agent.sh <project> <task-id> <role>
Day 2 当晚:成本追踪。因为账单吓到了,写了个脚本从 ccusage 抓 token 用量。
Day 3:容量管控(capacity governor)。同时启动 8 个 Agent,机器卡死。四行 bash 解决:数一下当前 tmux 会话数,到上限就拒绝新 spawn。
Day 3 之后:死亡 Agent 检测。会话挂了但任务文件还显示 “active”——加个心跳检查。
再后来:前任日志(predecessor log)。这个特别巧——任务失败重试时,新 Agent 从零开始,不知道前一个失败在哪。所以 spawn-agent 学会了去查同任务的失败记录,把日志拷进新 worktree 的 .predecessor-log。新 Agent 启动时先读这个,知道前任栽在哪,换条路走。
注意这个模式:每一个功能都不是设计出来的,是被打疼了才加的。你不会在 v1 设计文档里写”前任日志”,因为还没失败过。
五、当编排本身需要被编排:Autopilot 的诞生
到了 Day 3,作者面对一个新场景:BuildSolver pipeline——每个题目 7 个阶段,35 个题目,总共 245 个任务。手工管不可能。
于是 Autopilot 诞生了。它是一个跑在自己 tmux 会话里的 bash 脚本,干一个人类编排者会干的事:
- 轮询任务状态
- 依赖满足就 spawn Agent
- 失败自动重试
- 完成自动 merge
- 发现 planner Agent 中途生成的新任务,纳入管理
- 尊重容量上限(最多 4 个并发)
启动它,走人。回来一看:38 个题目分诊、辩论、构建、评分、部署完毕。160+ 任务,初始启动后零人工介入。
但 Autopilot 还揭示了一个更深的东西——Pipeline 需要 planner,planner 需要 debater(辩手)。
作者试过直接让 Coder Agent 上,结果很平庸。最后跑通的流水线是:
1
2
3
4
5
6
7
Planner (opus) → 读题目,产出详细规格
↓
Debater (opus) → 攻击规格,挑战假设,消歧
↓
Coder (sonnet) → 按辩论过的规格实现
↓
Quality (sonnet) → 给部署结果打分
Debater 这个阶段是单点提升最大的。一个经过对抗性审查的方案,质量明显高于直接写代码。这在人类团队里也成立,但 Terra 把它做成了强制、自动、一致——这才是关键。
六、那个”活在文件里”的 State
回到 compaction 失忆的问题——Terra 的答案是一个显式的 state 文件,orchestrator 在自然断点写、每次启动读。
1
2
3
4
5
6
7
8
9
10
{
"goals": ["当前高层目标"],
"tasks_context": {
"recently_completed": ["task-rdp05", "task-rdp06"],
"in_progress": ["task-rdp07", "task-rdp08"],
"blocked": ["task-edr03 — 等 devenv-gateway 部署"]
},
"next_steps": ["merge rdp07", "spawn rdp09 wave"],
"decisions_made": ["BuildSolver 全部使用 Cognito"]
}
这个设计的精髓在于:state 不属于任何一个会话。
- Orchestrator 凌晨 3 点崩了 → Watchdog 重启 → 新会话读这个文件继续
- Compaction 抹掉短期记忆 → 文件是 ground truth
- 你从地铁上用 Telegram 问”现在啥情况” → Bot 读同一个文件回答
会话只是看向 state 的窗口,不是 state 本身。 这个架构决策是 Terra 能跨天、跨端、跨崩溃运行的根本原因。
七、配角们:Janitor、Watchdog、Telegram Bridge
随着系统长大,三个支持脚本出现了:
- Janitor(清洁工):检测漂移——任务结束但 worktree 还在、tmux 会话死了但状态没更新、任务卡在 pending 超过 72 小时。安全的自动修,不安全的报警。
- Watchdog(看门狗):launchd service,每 5 分钟检查 orchestrator 是否还活着、心跳是否新鲜。出问题就重启 + Telegram 通知。
- Telegram Bridge:通过 inbox/outbox JSON 协议把消息转给 orchestrator。在通勤的地铁上问一句”editor 任务啥状态”,回来的是从任务文件和 Agent 状态读出来的真实答案,不是”建议你 SSH 上去看看”。
八、还有一个被严重低估的东西:项目 Wiki
每次你对一个代码库 spawn 一个 Claude Code 会话,它都要先探索。非平凡代码库要 5-10 分钟、烧不少 token。一天 spawn 30 个,就是 5 小时的重复探索。
Terra 的解法是给每个项目一个小型 vault:index.md 链接到架构、数据模型、路由、认证、代码地图等子页。Agent 从 5 分钟探索变成 5 秒阅读,直接跳到相关代码。
这是 harness 思维的一个微缩样本:你不只是观察模型的行为,你设计模型工作的条件。
九、回到核心论点:为什么 harness 就是产品
文章最有冲击力的一段,我直接转译过来:
同一个 Claude Sonnet,驱动着我的 Coder Agent,也驱动着别人的。差异化在角色定义、流水线阶段、质量门禁、上下文注入。通用框架不可能知道你的 planner 输出需要对抗性审查,也不知道你的部署 fork 在 merge 后需要同步检查。但你的 harness 知道。
这句话翻译成我们日常的语境:
- 模型层正在快速商品化,大家用的都是同一个 Sonnet/Opus
- 你的工程判断——任务怎么拆、pipeline 怎么排、什么阶段要复审、失败怎么处理——这才是不可复制的
- 而工程判断只有一个载体:你自己写的那层 harness
作者还提了一个我特别认同的观察:速度会复利。
Terra 第一天处理 1 个任务,第二周一天处理 100+。不是模型变好了,是 harness 变好了。每一次改进都让后面所有任务变快。
这是技术从业者最该警觉的一件事——如果你只是用 Claude Code 写代码,你在线性地积累价值;如果你在迭代自己的 harness,你在指数地积累价值。
十、所以,你下周一可以做什么?
把方法论从原文里榨干,给你一个最小起步路径:
第一步:写一个 spawn-and-merge 双脚本
spawn-agent.sh:创建 git worktree、拷角色 CLAUDE.md、放任务 JSON、tmux 启动 Claude Codemerge-work.sh:把 worktree 分支合回主干
这就是你的 MVP orchestrator。其它都是优化。
第二步:定义任务契约
不要写自然语言任务。任务是结构化 JSON:ID、title、description、acceptance criteria、dependencies、role。这样 orchestrator 才能程序化地解析状态。
第三步:写 state 文件
就一个 JSON:goals、in-progress、blocked、next steps、decisions。每个自然断点写一次。
第四步:等疼了再加东西
- 没遇到孤儿 worktree 之前,不要写 janitor
- 没经历过夜间崩溃,不要写 watchdog
- 没烧钱之前,不要写成本追踪
每个功能必须是对一个真实痛点的回应。
第五步:把 pipeline 看得比模型重要
Planner-Debater-Coder 这种结构化流水线 + Sonnet,效果好过单个 Opus Agent。分工和对抗性审查 > 原始能力。
最后
原文有一段话我想原样保留:
你可以拥有世界上最好的模型。如果你喂给它垃圾上下文,得到的还是垃圾输出。
我想再加一层:你可以拥有世界上最好的上下文。如果你没有一套系统把它一致地、跨数十个 Agent、跨数百任务、跨数周连续运行地应用——这个上下文也没用。
模型是引擎,上下文是燃料,harness 是你自己设计的那辆车。
模型会自己变好。harness 只有你动手才会变好。
原文链接:Harnessing the Harness — Ng Shangru,GovTech AI Practice
为什么值得读:少见的不谈”概念”、只谈”工程演化”的多 Agent 系统实战记录。